
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: muyang-0410
数据收集是整个数据生命周期的初始环节,埋点数据是驱动业务的指标,这一切都需要基于数据。那么,我们需要收集的数据有哪些?

谈到数据驱动业务,离不开数据是怎么来的,数据收集是整个数据生命周期的初始环节。
数据生命周期的大体介绍,在过去的一篇文章中有提到。虽然文章的部分内容我准备重新构造,但是对于这部分的基础环节,并没有太多的变换。
文章会涉及到不少技术相关的知识,我会尽量减少这部分的细节。相信经过一系列的讲解,你会明白埋点数据怎么成为驱动业务的指标,文章也会提供网上的公开数据,帮助你实际上手操作。
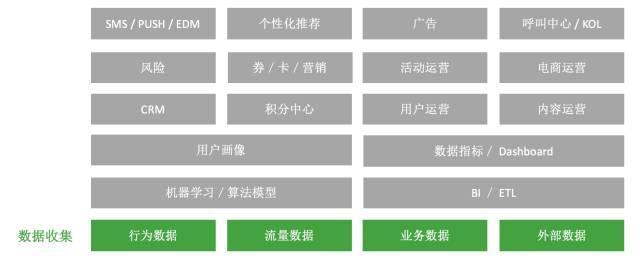
需要收集的数据主要能划分成四个主要类型:行为数据、网站日志数据、业务数据、外部数据。
一、Web日志数据
网站日志数据是Web时代的概念。
用户浏览的每一个网页,都会向服务器发送请求,具体的技术细节不用关注。只要知道,当服务器和用户产生数据交互,服务器就会把这次交互记录下来,我们称之为日志。
127.0.0.1 – – [20/Jul/2017:22:04:08 +0800] “GET /news/index HTTP/1.1” 200 22262 “-” “/5.0 (; Intel Mac OS X ) /537.36 (KHTML, like Gecko) /60.0.3112.66 /537.36”
上图就是一条服务器日志,它告诉了我们,什么样的用户who在什么时间段when进行了什么操作what。
127.0.0.1是用户IP,即什么样的用户。不同用户的IP并不一致,通过它能基本的区分并定位到人。[20/Jul/2017:22:04:08 +0800] 是产生这条记录的时间,可以理解为用户访问的时间戳。
“GET /news/index HTTP/1.1″是服务器处理请求的动作,在这里,姑且认为是用户请求访问了某个网站路径,/news/index。这里省略了域名,如果域名是,那么用户访问的完整地址就是,从字面意思理解,是用户浏览了新闻页。也就是what。
who、when、what构成了用户行为分析的基础。/5.0这个字段是用户浏览时用的浏览器,它的分析意义不如前三者。
如果我们基于who分析,可以得知网站每天的PVUV;基于when分析,可以得知平均浏览时长,每日访问高峰;what则能得知什么内容更吸引人、用户访问的页面深度、转化率等属性。
上面的示例中,我们用IP数据指代用户,但用户的IP并不固定,这对数据口径的统一和准确率不利。实际应用中还需要研发们通过或token获取到用户ID,并且将用户ID传递到日志中。它的形式就会变成:
127.0.0.1 – [20/Jul/2017:22:04:08 +0800]…
就是用户ID,通过它就能和后台的用户标签数据关联,进行更丰富维度的分析。
案例的服务器日志,记录了用户的浏览数据,是标准的流量分析要素。但是网站上还会有其他功能,即更丰富的what,譬如评论、收藏、点赞、下单等,要统计这些行为靠日志就力有未逮了。所以业内除了服务器日志,还会配合使用JS嵌入或者后台采集的方式,针对各类业务场景收集数据。
在这里我提供一份网上公开的数据集,年代比较古老,是学生在校园网站的浏览行为数据集。数据原始格式是log,可以txt打开。需要的同学可以在后台发送「日志下载」。
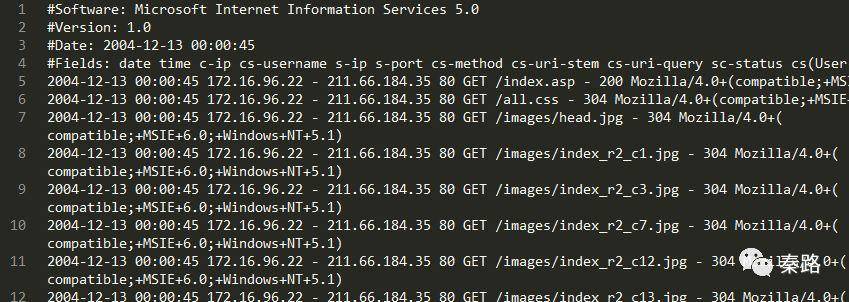
它是标准的服务器日志文件,对分析师来说,IP,时间、浏览了哪些网页,这三个字段足够做出一份完整的分析报告。后续的章节我将围绕它进行演练,为了照顾新手,会同时用Excel和演示。
首先进行简单的清洗。如果是Excel,直接将内容复制,文件开头的内容只需要保留第四行信息,它是数据的字段。将内容复制黏贴到Excel中。
按空格进行分列,初步的数据格式就出来了。
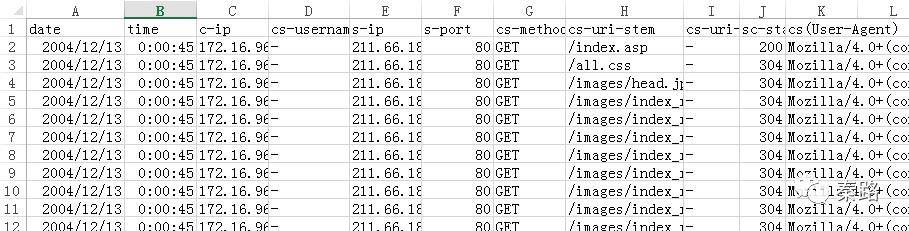
我们仔细观察cs-uri-stem,会发现有很多无用数据。比如//.jpg,它是向服务器请求了图片数据,对我们分析其实没有多大帮助。用户访问的具体网页,是/index.asp这类以.asp为结尾的。
利用过滤功能,将含有.asp字符串的内容提取出来,并且只保留date、time、c-ip、cs-uri-stem、cs-uri-stem。按c-ip和time按从小到大排序,这样用户在什么时间做了什么的行为序列就很清晰了。

像172.16.100.11这位游客,在凌晨30分的时候访问了网站首页,然后浏览了校园新闻和一周安排相关的内容,整个会话持续了半小时左右的时间。
相关的清洗留待下一篇文章,这里就不多花时间讲解了。感兴趣,大家可以先自行练习一下。
二、APP行为数据
数据埋点,抽象理解便是记录用户在客户端的关键操作行为,一行数据便等于一条行为操作记录。点击「立即抢购」是,在文章页面停留5min是,发表文章评论是,进行退出登录操作是,视频网站首页看到了10条新视频的内容曝光也是…反必要的,我们都采集。
APP行为数据是在日志数据的基础上发展和完善的。虽然数据的载体是在APP端,但它同样可以抽象出几个要素:who、when、where、what、how。
who即唯一标识用户,在移动端,我们可以很方便地采集到,一旦用户注册,就会生成新的。
这里有一个问题,如果用户处于未登录状态呢?如果用户有多个账号呢?为了更好地统一和识别唯一用户,移动端还会采集,通过手机设备自带的唯一标识码进行区分。
实际的生成逻辑要复杂的多,安卓和iOS不一样,只能趋近于唯一、用户更换设备后怎么让数据继承,未登录状态的匿名账户怎么继承到注册账户,这些都会影响到分析的口径,不同公司的判断逻辑不一致,此处注意踩坑。
回到用户行为:
如果我们想知道用户的点赞行为,那么在用户点赞的时候要求客户端上报一条like信息即可。
如果只是到这里,还称不上埋点,因为点赞本身也会写入到数据库中,并不需要客户端额外采集和上报,这里就引入了全新的维度:how。
如何点赞,拿微信朋友圈举例。绝大部分的点赞都是在朋友圈中发送,但是小部分场景,是允许用户进入到好友的个人页面,对发布内容单独点赞的。服务端/后台并不知道这个点赞在哪里发生,得iOS或安卓的客户端告诉它,这便是how这个维度的用处。
换一种思考角度,如果很多点赞或留言的发生场景不在朋友圈,而是在好友个人页。这是不是能讨论一下某些产品需求?毕竟朋友圈信息流内的内容越来越多,很容易错过好友的生活百态,所以就会有那么一批用户,有需要去好友页看内容的需求。这里无意深入展开产品问题,只是想说明,哪怕同样是点赞,场景发生的不同,数据描述的角度就不同了:朋友圈的点赞之交/好友页的点赞至交。
除了场景,交互行为方式也是需要客户端完成的。例如点击内容放大图片、双击点赞、视频自动播放、触屏右滑回退页面…产品量级小,这些细节无足轻重,产品变大了以后,产品们多少会有这些细节型需求。
行为埋点,通常用json格式描述和存储,按点赞举例:

是嵌套的json,是描述行为的how,业内通常称为行为参数,event则是事件。指的是怎么触发点赞,page是点赞发生的页面,是页面的类型,现在产品设计,在推荐为主的信息流中,除了首页,还会在顶栏划分子频道,所以page=feed,=game,可以理解成是首页的游戏子频道。指对哪篇具体的内容点赞,是内容类型为视频。
上述几个字段,就构成了APP端行为采集的how和what了。如果我们再考虑的齐全一些,who、when及其他辅助字段都能加上。
埋点怎么设计,不是本篇文章的重点(实际上也复杂的多,它需要很多讨论和文档and so on,有机会再讲),因为各家公司都有自己的设计思路和方法,有些更是按控件统计的无痕埋点。如果大家感兴趣,可以网络上搜索文章,不少卖用户分析平台的SaaS公司都有文章详细介绍。
除了行为「点」index.asp,埋点统计中还包含「段」的逻辑,即用户在页面上停留了多久,这块也是客户端处理的优势所在,就不多做介绍了。
这里提供一份来源于网上的我也不知道是啥内容产品的行为数据源,虽然它的本意是用作推荐模型的算法竞赛,不过用作用户行为分析也是可以的。
这几个字段便是用户行为的基础字段,像,虽然没有明确说明是什么含义,但也猜测是描述了用户浏览的深度,比如看了50%+的文章内容,它只能以客户端的形式统计,实际业务场景往往都需要这种有更深刻含义的数据。
具体的分析实操留待下一篇文章讲解,感兴趣的同学可以自行下载,和网页日志放一起了。
行为数据不是百分百准确的,采集用户行为,也会有丢失和缺漏的情况发生。这里不建议重要的统计口径走埋点逻辑,比如支付,口径缺失问题会让人很抓狂的,相关统计还是依赖支付接口计算。支付相关的埋点仅做分析就行。
APP行为数据往往涉及到大数据架构,哪怕10万DAU的一款产品,用户在产品上的操作,也会包含数十个乃至上百的操作行为,这些行为都需要准确上报并落到报表,对技术架构是一个较大的挑战。而行为数据的加工处理,也并不是mysql就能应付,往往需要分布式计算。
对数据源的使用方,产品运营及分析师,会带来一个取舍问题。如果我只想知道点赞和分享数,那么通过api或者生产库也能知道,是否需要细致到行为层面?这便是一个收益的考量。
当然啦,我个人还是挺建议对分析有兴趣的同学,去能接触到用户行为数据的公司去学习。
三、业务数据
业务数据是生产环境提供的,我们在APP端获得了用户,文章或商品的,乃至支付,但它们只和用户的行为有关。换句话说,我并不知道是什么样的用户。
是男是女,芳龄几何?出生籍贯,从哪里来?这些人口统计学的信息必然不会在行为埋点中包含。商品内容订单也是同理。
单依靠埋点的行为数据,我们并不能准确描述什么样的用户做了事情,也不知道对什么样的内容做了行为。描述性质的数据/维度是分析的价值所在。男女的行为差异,不同城市的用户群体购买习惯,这才构成了分析和精细化的基础。
业务数据和行为数据的结合,在数据层面上可以简单理解为join。比如把用户行为数据的和存放用户信息的进行关联起来。形成如下:
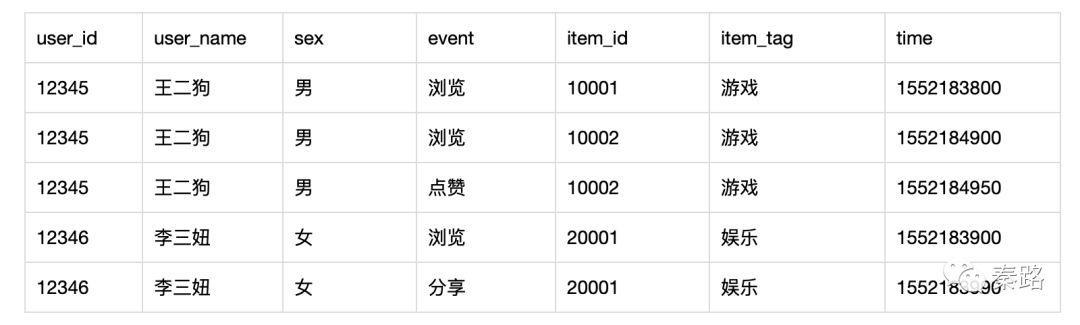
上图是简化后的字段。和sex就是取自业务数据的用户信息,也是取自内容信息表中的字段,而event则来源于行为埋点。三者共同构成了,什么样的用户who在什么时候when对什么样的内容做了什么事what。
简单说,很多用户行为的建模,就是拿各种数据组合在一起计算。用的粒度聚合,你算得是这些用户喜欢哪些文章index.asp,用的粒度聚合,你算得是这篇文章被哪类用户喜欢。它们都是你看待/分析事物的角度。
从更深的层面上说,行为数据也是可以再加工和利用的,它是构成用户标签的基础。拿浏览行为数据说,我们设计了埋点,知道王二狗看了哪些类型的文章,

是文章类型,游戏、娱乐、科技这类。有些用户可能各种各样的类型都喜欢,有些用户的口味偏好则比较集中,产品上可以拿用户偏好来代称,这里专指兴趣的集中度。
现在取所有用户的浏览数据,算它们在不同类型tag下的浏览分布(上文提供的行为数据就可以计算,便是内容类型)。比如王二狗可能90%的浏览都是游戏,10%是其他,那么就可以认为王二狗的兴趣集中度高。
这里有一个很简易的公式,1-sum(p^2),将所有内容类别的浏览占比平方后相加,最终拿1减去,就算出了用户兴趣的集中程度了。我们拿案例简单看下。
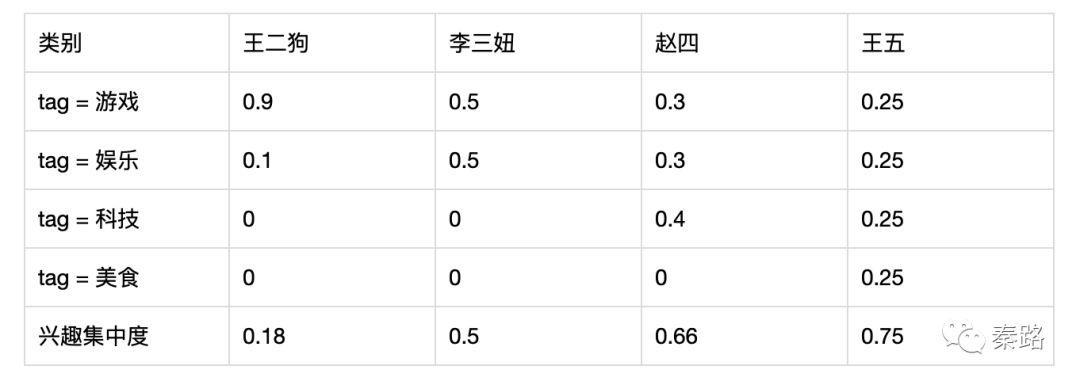
上图的李二狗,他的兴趣90%集中在游戏,所以兴趣集中度= 1 – (0.9*0.9+0.1*0.1)=0.18,李三妞的兴趣稍微平均点,所以1-(0.5*0.5+0.5*0.5)=0.5,兴趣集中度比王二狗高。
赵四有三个兴趣点,所以比李三妞稍微高一些,王五是均衡的,所以是四人中最高的。可能有同学疑问,兴趣程度为什么不用标准差算呢?它也是算波动偏离的呀,这是一个思考题,大家可以新加一个tag类别再算一下。
1-sum(p^2)是趋近于1的,有四个类别,一位均衡的用户(四个都是0.25)是0.75的集中度,当有十个类型,一位均衡的用户(四个都是0.1)是0.9的集中度。这种公式的好处就是兴趣类别越多,集中度的上限越接近1,这是标准差比不了的。
这里并没有涉及太高深的数学模型,只是用了加减乘除,就能快速的计算出兴趣的集中程度了。通过行为数据算出用户兴趣集中度,便能在分析场景中发挥自己的用武之地了,它是用户画像的基础,以后有机会再深入讲解。
四、外部数据
外部数据可以分为两个部分,一个是行业市场调研类的,一个是爬虫抓取的,它们也能作为数据源分析,比如站外热点内容和站内热点内容、竞品对手商家表现和自己产品的商家,大家有机会应用的不多,就不多讲了,我也不怎么熟。
到这里为止,文章主要讲了用户行为层面的数据是怎么来的,更多是基础概念的讲解。不过,因为数据来源于网上,数据的丰富程度还是欠缺了不少,说白了,业务场景比较弱,希望大家自己在工作中多思考。
#专栏作家#
秦路,微信公众号ID:,人人都是产品经理专栏作家。
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: muyang-0410




