前言
在学习编程的过程中,我们可能听说过正则表达式,但不知道它是什么。 当我第一次听说正则表达式时,我想知道正则表达式是什么? 它是做什么用的? 难学吗? 可能很多人跟我的想法一样。 学完之后,我会认真负责的告诉大家,正则表达式并不难! ! !
正则表达式
百度百科写道:
正则表达式,又称正则表达式,是计算机科学中的一个概念。 正则表达式通常用于检索和替换符合某种模式(规则)的文本。 它是字符串操作的逻辑公式。 一个“规则串”,这个“规则串”用来表达一个对字符串的过滤逻辑。
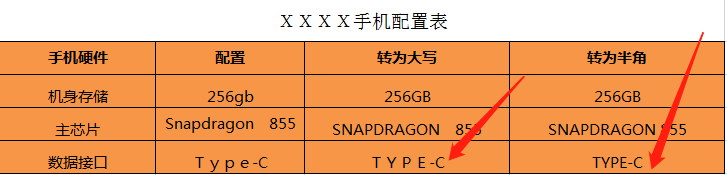
我们打开开源中国提供的正则表达式测试工具#,输入要匹配的文本,然后选择要匹配的表达式,这样就可以得到结果了,如下图:
简单来说,正则表达式是处理字符串的利器。 它有自己特定的语法结构。 有了它,可以轻松地检索、替换、匹配和验证字符串,并在 HTML 中提取所需的信息。 单一的东西。
有的人可能会说下面是什么,他们看不懂。
[a-zA-z]+://[^s]*
即正则表达式特定语法规则的组合。 通过这些组合,我们就可以得到我们想要的字符。 例如,s 表示匹配任意空白字符,* 表示匹配任意数量的前面字符,等等。 常用匹配字符规则如下:
模式描述
w
匹配字母、数字和下划线
W
匹配非字母、数字和下划线的字符
s
匹配任何空白字符,相当于 {tnrf}
S
匹配任何非空白字符
d
匹配任意数字,相当于[0-9]
D
匹配任何非数字字符
A
匹配字符串的开头
Z
匹配字符串的结尾,如果有换行符,只匹配换行符之前的字符串
z
匹配字符串的结尾,如果有换行符,也匹配换行符
G
match 上次完成比赛的地方
n
匹配换行符
t
匹配标签
^
匹配一行字符串的开头
$
匹配一行字符串的结尾
.
匹配除换行符以外的任意字符,当指定re.DOTALL标志时,可以匹配包括换行符在内的任意字符
[…]
用来表示一组单独列出的字符,比如[amk]匹配a,m,k
[^…]
不在[]中的字符,如^abc,表示匹配除a,b,c以外的字符
*
匹配 0 个或多个表达式
+
匹配 1 个或多个表达式
?
匹配前面正则表达式定义的 0 或 1 个片段(非贪婪匹配)
{n}
恰好匹配 n 个前面的表达式
{n,m}
匹配n到m次,与前一个正则表达式匹配的段(贪心匹配)
一|乙
匹配 a 或 b
( )
匹配括号中的表达式,也表示一个组
看到上面的表格是不是有点害怕? 在爬虫中,使用频率最高的匹配字符如下:
记住上面最常用的匹配字符。 在接下来的学习中,如果遇到其他匹配的字符,我们会做一个简单的解释。 当然,如果你想了解更多的匹配角色,可以去看菜鸟教程。
re library – 查找匹配项的常用方法
match():从字符串开头开始匹配,匹配不成功则返回None。
search():匹配整个字符串,返回第一个匹配成功的值,否则返回None;
fullmatch():匹配整个字符串是否与正则表达式完全相同,否则返回None。
其语法格式为:
re.match(pattern,string,flags=0)
re.search(pattern,string,flags=0)
re.fullmatch(pattern,string,flags=0)
在:
pattern 表示匹配的正则表达式或字符串;
string 表示匹配的字符串;
flags代表标准位,用于控制正则表达式的匹配方式,也可以忽略,如:是否区分大小写。
具体代码如下:
import re
print(re.match('Hello,Word','Hello,WOrd'))
print(re.search('e.*?$','hello Word'))
print(re.fullmatch('e.*?$','Hello Word'))
运行结果为:
None
<re.Match object; span=(1, 10), match='ello Word'>
None
在re.match()方法中,第一个参数是一个字符串,第二个参数是要匹配的字符串。 由于两个字符串中的字母o不同,所以匹配不成功,返回值为None;
re.search()方法中,第一个参数是一个正则表达式,表示匹配0个或多个从字母e开始的任意字符,匹配前面正则表达式定义的段到字符串结尾,第二个parameter为要匹配的字符串,输出结果中object为输出对象类型,span=(1,10)表示匹配范围为1到9,match='ello Word'表示匹配的内容;
re.fullmach() 方法类似于 re.match() 方法。 第一个参数是正则表达式,第二个参数是要匹配的字符串。 由于要匹配的字符串与正则表达式不匹配,所以返回值为None。
注意:找到一个匹配项将返回一个匹配对象。
找到多个匹配项
re.findall:在字符串的任意位置查找正则表达式匹配的字符,并返回一个列表,如果没有找到匹配,则返回一个空列表;
re.finditer:在字符串的任意位置查找正则表达式匹配的字符,返回一个迭代器;
语法格式为:
re.findall(pattern, string, flags=0) 或 pattern.findall(string , n,m)
re.finditer(pattern, string, flags=0)
在:
具体代码如下:
import re
fd1 = re.findall('D+','11a33c4word34f63')
pattern = re.compile('D+')
fd2 = pattern.findall('11a33c4word34f63', 0, 10)
fi=re.finditer('D+','11a33c4word34f63')
print(fd1)
print(fd2)
print(fi)
运行结果为:
['a', 'c', 'word', 'f']
['a', 'c', 'wor']
在第二行代码中正则表达式忽略大小写,我们使用re.findall(pattern, string, flags=0)语法,第一个参数是由D+简单匹配字符组成的正则表达式,表示匹配1个或多个任意非数字字符,第二个参数是要匹配的字符串,所以匹配的内容是acwordf正则表达式忽略大小写,没有匹配到的字符作为列表的分割点,所以返回的内容是['a', 'c', 'word', 'F'];
在第三行代码中,我们使用re.compile()方法将正则字符串编译成正则表达式对象(这个re.compile()方法会在后面介绍),在第四行代码中,调用pattern对象使用了findall()方法,第一个参数是要匹配的字符串,后面两个数字是匹配字符串的开始和结束位置,所以返回的内容是['a', 'c', '世界'];
第五行代码,我们使用了re.finditer()方法,第一个参数是正则表达式,第二个参数是要匹配的字符串,返回内容中的callable_iterator代表一个迭代器。 我们用for循环打印出来的匹配成功的字符串是什么?
fi=re.finditer('D+','11a33c4word34f63')
for i in fi:
print(i)
运行结果为:
<re.Match object; span=(2, 3), match='a'><re.Match object; span=(5, 6), match='c'><re.Match object; span=(7, 11), match='word'><re.Match object; span=(13, 14), match='f'>
匹配内容与findall方法相同。 当可能有大量匹配项时,我们推荐使用finditer方法,因为findall方法返回的是一个列表,这个列表是一次性在内存中生成的,而finditer方法返回的是一个迭代器。 迭代器是在需要使用的时候一点一点生成的,内存占用比较好。
分割
re.split():根据可以匹配到的子串拆分字符串,返回列表。
语法格式为:
re.split(pattern, string ,maxsplit=0, flags=0)
在:
具体代码如下:
sp1=re.split('d+','I5am5Superman',maxsplit=0)sp2=re.split('d+','I4am5Superman',maxsplit=1)sp3=re.split('5','I4am5Superman',maxsplit=0)print(sp1)print(sp2)print(sp3)
运行结果为:
['I', 'am', 'Superman']['I', 'am5Superman']['I4am', 'Superman']
在第二、三、四行代码中,我们使用了re.split()方法,我们使用正则表达式或者数字作为分割点,并设置分割的次数。
注意:str 模块也有一个 split 方法。 主要区别是str.split不支持正则拆分,re.split支持正则拆分;
代替
re.sub():用于替换字符串中的匹配项;
re.subn():用于替换字符串中的匹配项,返回一个元组。
语法格式为:
re.sub(pattern, repl, string, count=0, flags=0)re.subn(pattern, repl, string, count=0, flags=0)
在:
具体代码如下:
import re
def loo(matchobj):
if matchobj.group(0)=='1':
return '*'
else:
return '+'
print(re.sub('w+',loo,'1-23-123-ds-fas23221'))
print(re.sub('d+','1','1-23-123-ds-fas23221',count=2))
print(re.subn('w+','1','1-23-123-ds-fas23221adsa2'))
运行结果为:
*-+-+-+-+1-1-123-ds-fas23221('1-1-1-1-1', 5)
首先,我们定义一个loo函数,它的作用是根据字符返回一个特定的字符。 第七行和第八行使用re.sub(),repl传入的参数分别是函数和字符。 第一个sub()没有传入count数据,所以替换所有匹配,第二个sub()传入count数据为2,所以替换前两个匹配的数据;
在第九行代码中,我们使用 re.subn() 方法,它返回一个元组。 传入的第一个参数是正则表达式,用于匹配字母、数字和下划线,第二个参数是要替换得到的字符,第三个参数是要查找替换的原字符串,因为我们已经替换了5次,所以返回是 ('1-1-1-1-1', 5)。
正则表达式对象
re.compile():将正则字符串编译成正则表达式对象。
其语法格式为:
re.compile(pattern,flags)
在:
具体代码示例如下:
import re
pattern=re.compile('w+')
content='I-am-superman'
result=re.findall(pattern,content)
print(result)
运行结果为:
['I', 'am', 'superman']
首先我们调用compile方法创建一个正则表达式对象,定义一个content变量来存放字符串,然后调用findall()方法将匹配到的字符串以列表的形式输出。 compile()方法就是对正则表达式进行封装,以便我们更好的复用,使得我们在调用search()方法、findall()等方法时不需要重写正则表达式。
re 库 – 修饰符
正则表达式可以包含一些可选的标志修饰符来控制匹配的模式。 修饰符被指定为可选标志。 可以通过按位 OR(|) 来指定多个标志。 例如re.I和re.M设置为I和M标志位,必要时也可以使用一些修饰符,如下表所示:
修饰符说明
re.I 或 re.IGNORECASE
使匹配不区分大小写
re.L 或 re.LOCALE
进行语言环境感知匹配
re.M 或 re.MULTILINE
多行匹配,影响 ^ 和 $
re.S 或 re.DOTALL
制作 。 匹配所有字符,包括换行符
re.A 或 re.ASCII
只匹配 ASCII,不匹配 Unicode
re.X 或 re.VERBOSE
此标志允许您通过提供更灵活的格式来编写更容易理解的正则表达式
以我们网页匹配中常用的re.I和re.S为例。
具体代码示例一如下:
import re
#修饰符re.I
print(re.findall('SUPERMAN','i am superman'))
print(re.findall('SUPERMAN','i am superman',re.I))
#修饰符re.S
print(re.findall('.*?','nman',))
print(re.findall('.*?','nman',re.S))
运行结果为:
[]
['superman']
['', '', 'm', '', 'a', '', 'n', '']
['', 'n', '', 'm', '', 'a', '', 'n', '']
当不添加 re.I 和 re.S 修饰符时,
由于大写,第一个输出为空;
由于匹配时会自动忽略特殊字符的匹配,所以第三个输入没有换行符(n)。
匹配目标的提示
如何提取一段文本中的部分内容,我们可以用()括号把我们要提取的子串括起来,它标示了一个子表达式的开始和结束位置,每个标示的子表达式都会对应每一个A组,调用group()方法传入分组索引,得到提取结果。
具体示例代码如下:
import re
content='I am superman,It is cool123'
result=re.match('^Is(w+)ssup.*?isscool(d+)',content)
print(result.group(0))
print(result.group(1))
print(result.group(2))
运行结果为:
I am superman,It is cool123am123
首先,我们调用了re.match()方法进行匹配,然后调用group()方法传入组的索引。 这里我们用了两个(),所以索引最大为2。
如果正则表达式后的()括号内有内容,则可以依次使用group(3)和group(4)获取。
贪心和非贪心匹配
.*:贪心匹配就是匹配尽可能多的字符;
.*?:非贪婪匹配匹配尽可能少的字符。
它们的区别在于多了一个问号。 下面通过具体的代码来感受下它们的区别。
具体代码如下:
import re
content='I am 123superman,It is cool'
#贪婪匹配.*
result=re.match('^I .*(d+).*cool',content)
print(result)
print(result.group(1))
#非贪婪匹配.*?
result1=re.match('^I .*?(d+).*?cool',content)
print(result1)
print(result1.group(1))
运行结果为:
<re.Match object; span=(0, 27), match='I am 123superman,It is cool'>
3
<re.Match object; span=(0, 27), match='I am 123superman,It is cool'>
123
在匹配内容上,贪心匹配和非贪心匹配的全部匹配内容是一样的,但是贪心匹配的目标匹配内容会少一部分,因为贪心匹配会匹配尽可能多的内容。
匹配时,尽量使用非贪心匹配,避免丢失匹配结果。
实践练习
下面来实战一下,尝试爬取QQ音乐中的热歌排行榜、图片链接、歌名、歌手和播放时间等信息,并将这些信息存储在一个csv文件中。
本次爬取的基本思路:
页面分析;
抓取页面源代码;
定期提取我们想要的信息;
将信息保存到 csv 文件。
页面分析
首先我们在chrome浏览器中打开QQ音乐热歌榜,打开开发者工具,如下图:
我们观察到,存放排行榜信息的容器在
…
, 展开这个
…..
,观察里面的信息,如下图:
展开后我们发现里面有两个ul,第二个ul里面有很多li,每一个li对应一首歌的信息,这是我们后面构造正则表达式的基础。
抓取页面源码
首先,我们定义一个 get_page() 方法来获取页面的源代码。 具体代码如下:
import re
import requests
import csv
#获取页面源代码
def get_page():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
response=requests.get('https://y.qq.com/n/ryqq/toplist/26',headers=headers)
if response.status_code==200:
html=response.text
parse_page(html)
return None
上面代码中,首先导入了re、requests、csv库,然后我们构造了一个请求头headers,然后调用requests.get()方法,将我们需要获取的源代码的url传给它,如果网页当响应状态码为200时,会调用parse_page()方法,我们传入的参数是Unicode数据。 这样我们就成功的抓取了QQ音乐热歌榜的源码并传输了源码。
定期提取
在上一步中,我们已经成功提取了源代码。 接下来,我们需要构造一个正则表达式来提取我们想要的内容,并将其存储在字典中。 这里我们使用非贪婪匹配。
首先我们先获取排名,打开开发者工具,找到排名信息源代码所在的地方,如下图:
在上图中,我们可以看到排名代码的信息。 我们根据这些信息构建排名的正则表达式。 因为一里对应一首歌,所以我们正则表达式的开头是
送书
又到了每周三送书的时候了,今天为大家带来的是“剑指大优惠”。
自2014年开播以来,《剑指offer》(以下简称“经典版”)在豆瓣的评分不降反升,目前评分高达9.3分!
不容错过的内幕交易
49元包邮
快扫二维码下单吧!
您最喜欢的优惠正在向您招手
公众号回复:送书,参与抽奖(共3本书)